エラーレポートからコード変更までをシームレスに接続する
ソースコード各行がどういった意図を持つのか、各変更がなぜ必要だったのかという経緯を把握することは、コードリーディングにおいて言うまでもなく重要なプロセスです。
しかしコードと合わせて貴重な文脈情報を記録するには多くの努力が必要だというのもまた事実です。いちいちコメントを残す手間も無視できませんし、そもそも変更の動機が文章化されているとも限らないからです。
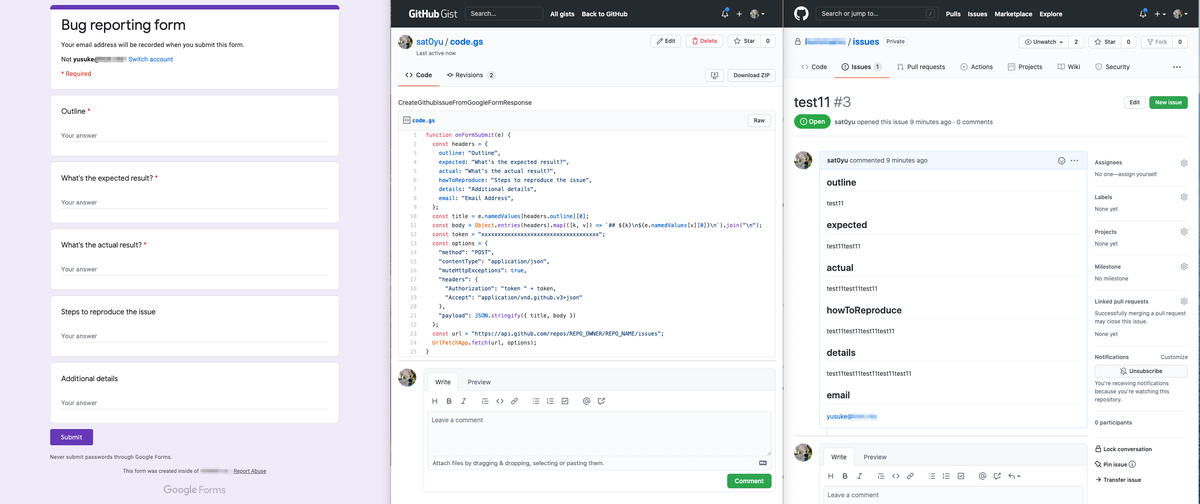
本記事ではエラーレポートからコード変更履歴までをシームレスに接続する方法を紹介します。 具体的にはGoogleFormsとGithubをGoogleAppScriptで連携させることで、Webフォームでエラーレポートを投稿すると自動的にGithub issueが起票されるよう設定します。
Githubが提供する数多くの機能の中でもissueやpull requestを相互に自動リンクできる機能は、コードトラッキングをする上で欠かせない機能です。
エラーレポートにとどまらず、新機能の提案や仕様変更にまつわる議論までプロダクトに関するすべての情報がGithub issueに集約されていればどれほど嬉しいことでしょう。 コードを読みながら関係者を一人ひとりを訪ねて情報収集する必要はなくなります。
しかしながらGithubは万人のためのツールではありません。ユーザの向き不向きに応じて適切なUIを提供する必要があります。
偶然発見したエラーを報告するために滅多に使わないサービスのアカウントでログインし、慣れないマークダウンと格闘し、ようやく仕上げてもらったレポートには肝心なエラー再現方法が書かれていなかった。そんな結末はあまりにも残念です。
- (1) レポート作成にログインが不要(もしくは日頃からログイン済みサービス)で、
- (2) 簡潔なフォーマットが定まっていて、
- (3) エラーが解決したあともレポートの価値が残る(コードベースと紐付く)、
このようなエラーレポートの方法があれば、報告者の負担も少なく、またエンジニア側も効率的に情報を探すことができます。
世の中にはたくさんの便利な(そして高価な)開発管理ツールがありますが、ここではとくにGoogleFormsとGithubを連携させることで実現させようと思います。 GoogleFormsなら(1)と(2)はある程度の改善が見込めそうです。(3)についてもGithubへ情報をエクスポートできれば解決できます。
前置きが長くなりましたが、仕組みの構築自体はGoogle/Githubが提供しているサービスを使うので多くを説明する必要はないと思います。 彼らの提供するWebコンソールは日々使いやすいようにアップデートされているため、構築方法をスクリーンショットつきで仔細に説明してもすぐに古くなってしまいます。
その代わり、GoogleForms <-> Github issueの連携のキモとなるGoogleAppScriptのソースコードを載せておきます。
headers 変数にはGoogleFormsで作成した質問項目のタイトルをいれます。
スクリプト中段のtokenにはGithubのPrivateAccessTokenを設定してください。権限はrepoが必要です。
REPO_OWNER および REPO_NAME はissueを作りたいGithubリポジトリの値で置き換えてください。
両サービスの連携が正しく設定できれば、本記事添付のスクリーンショットのようにGoogle Formsで投稿した内容をもとに自動でGithub issueが起票されます。
ちなみに読みやすいブログ記事を書くためには「ですます調」を心がけると良いらしいです。 本記事でさっそく試してみました。
rustでのクロージャとの上手い付き合い方
Javascript(Typescript)をはじめとして、関数型言語のエッセンスを取り入れた多くのプログラミング言語では「クロージャ」を利用できる。実際に自分もTypescriptを書く際にはクロージャのおかげで疎結合を保った実装ができたり、大変便利なテクニックだと気に入っている。
先日からRustを書き始めたのだが、その際にクロージャの書き方・扱い方が随分と難しくて苦労してしまった。 そこで本記事では、クロージャとオブジェクトの関係性を理解し、Rustにおけるクロージャとの上手い付き合い方を探る。
TL; DR
- クロージャ=環境+操作
- クロージャはオブジェクトと機能的な変換が可能
- クロージャで書こうとして5分迷ったらオブジェクトで書き直す
クロージャとは
まずはクロージャが一体何者なのかを理解する。
概念的にはクロージャは関数の一種にあたり、クロージャを使う側はそれがクロージャであるか否かを意識しない。 クロージャを特徴づける性質むしろクロージャを造る側・渡す側の視点から観察する必要がある。
クロージャを語るための大前提として、クロージャは自身の引数以外の変数(a.k.a. 自由変数)を字句的なスコープ(a.k.a レキシカルスコープ)解決*1によって参照する仕組みに立脚する点に触れておく。
次のコードにおいて、foo(に束縛される無名関数)は変数xを引数として受け取っていない。しかしレキシカルスコープに従って参照を解決するため、(main関数の先頭で10に束縛されている)変数xを見つけることができる。
// rustはレキシカルスコープなので10が出力される fn main() { let x = 10; let foo = || { dbg!(x) }; let bar = || { let x = 20; foo(); }; bar(); }
ここで上記rustのコード例をよく見てみると、bar(に束縛された無名関数)は変数fooしか知らないのに、間接的にfooの外側にあるxを使っていることに気がつく*2。
関数とは入力に対して出力が一意に定まる静的な存在のはずだ。それなのに関数(foo)に入力として与えていない情報(x)を使っている。なぜだろうか。
この挙動は「fooが環境を捉えている(変数xを束縛している)」と表現される。そしてまさに「環境を捉える」という性質こそがクロージャを理解する要点のひとつになる。
クロージャが”環境”を捉えることで、クロージャを使う側は”環境”の存在を意識する必要がなくなる。そうでなければ、クロージャ(もはやクロージャではなく純粋関数)を使う側がすべての情報を入力として与えなければいけない。
言い方を変えれば、クロージャをうまく利用することで情報(環境)を隠蔽しモジュールを疎結合に保つことができる。
蛇足だが字句的なスコープ解決を行わない言語ではクロージャを利用できない。具体的にはダイナミックスコープ*3しかサポートしないBashスクリプトではクロージャが書けない。
GDB online Debugger | Code, Compile, Run, Debug online C, C++
# bashスクリプトはダイナミックスコープなので20が出力される x=10 foo () { echo $x } bar () { local x=20 foo } bar
クロージャとオブジェクトの変換
クロージャを用いて情報を隠蔽する方法について触れたが、情報の隠蔽は何もクロージャの専売特許ではない。 オブジェクト指向の世界でも、不要な情報はprivateメンバとして外から隠し、振る舞い(メソッド)を用いてオブジェクトを操作する。
例えば以下において、関数recordは引数aの実体は知らないが、aがmake_soundを備えていることを知っていてそれを実行できる。 これは呼び出し側が知る必要のない情報(name)をCat構造体が隠蔽していることを意味する。
trait Animal { fn make_sound(&self) -> String; } struct Cat { name: String } impl Animal for Cat { fn make_sound(&self) -> String { format!("{} says \"meow\"", self.name) } } fn record (a: impl Animal) { // 説明のためにAmimalトレイトを使っているがrecord(c: Cat)としても変わりはない println!("{}", a.make_sound()); } fn main () { let c = Cat { name: "Einstein".to_string() }; record(c); }
ところで冒頭でも述べたとおり、クロージャを使う側はそれがクロージャであるか否かを意識せずに(必要であれば引数を受け取りながら)実行できる対象=関数であることだけを知っている。 この構造はたった今見たrecord関数とAnimalトレイト(あるいはCat構造体)の関係と相似している。
実際に上の例はクロージャを用いて書き換えることができる。 関数recordが引数aの実体を知らなくても済んだように、record_with_closure関数も変数cat_nameを認知することはない。
fn record_with_closure(make_sound: impl Fn() -> String) { println!("{}", make_sound()); } fn main() { let cat_name = "Einstein".to_string(); let c = || { format!("{} says \"meow\"", cat_name) }; record_with_closure(c); }
じつはオブジェクトとクロージャはお互いに変換することが可能だ*4。 オブジェクトの状態(name変数)とクロージャの環境(cat_name変数)が対応し、オブジェクトのメソッド(make_soundメソッド)とクロージャ自身に相当する。 オブジェクトを渡す場合には実行側がメソッド名を知っている必要があるが、クロージャであればそもそも実行しかできないので迷う必要がない。
さて、一見するとクロージャを用いたコードのほうが短く簡単なように感じる。 ではオブジェクトを使ったコードをクロージャーを用いてシンプルに書き換える方法があればそれで十分なのだろうか。
じつはクロージャーがFutureを返す場合(非同期処理)*5や、マルチスレッド環境でクロージャーを使う場合など、他の条件が重なった途端に状況が一転する。
例えばクロージャーがFutureを返す場合は impl Fn() -> dyn Future<Output = String> のような型宣言が想像できるが、実際にはクロージャーを実行しawaitするコードを書いた途端にコンパイルエラーで弾かれる。なぜならrustにおいてローカル変数はすべて事前に大きさが分かっている必要があり、dyn Future<Output = String>だけではその情報が足りないからだ(Sizedトレイトを要求される。)かといって、impl Fn() -> Box<dyn Future<Output = String>>などと書けば今度はUnpinトレイトが必要だと指摘される…。
このように、クロージャーを自由に渡せるJavascriptの世界とは違い、rustでクロージャーを扱うには言語に関する広く深い理解が求められる。一方でオブジェクトを使った書き方であれば、基本的な言語知識だけでも簡単に表現できる。
だからこそ、「クロージャーとオブジェクトが変換可能」であるという知識と「クロージャーで書こうと思っていた処理をオブジェクトを使って書き直す」あるいは「オブジェクトを渡していた処理をクロージャーを使って簡潔に書き直す」テクニックを備えておくことが大事になる。
おまけ
オブジェクトを使って非同期処理を渡す際にはasync-traitライブラリが非常に便利だ。 本ライブラリがあればtrait定義でasyncキーワードが使えるようになる。 github.com
おわり
rustに十分に習熟していればいざ知らず、自分のようなビギナーにとってはコンパイルエラーは強敵だ。いとも簡単に作業時間が溶けていく。ランタイムのエラーと異なり、コンパイルエラーはプログラマの精神を削る。何しろ手元になにも動くものが生まれないから。
かっこよく・スマートに書けなくても、まずは迅速に動くものを造る試す届けるために本記事でみてきたテクニックを使ってもらいたい。
rustのwebフレームワークgothamがtokio1.0対応したので使ってみた
せっかく読んでくれる方を落胆させないよう予め期待値調整をしておきたい。
自分自身はrustを書き始めたのはつい一ヶ月前ほどで、正月に自転車本を読んで勉強した程度の知識しかない。
最近うれしいことに、HTTPインタフェースをもったサービスをrustで構築する機会があった。 本記事ではそこで得られた知見(と言うほどのものでは無いかもしれないが)を残しておく。 多プログラミング言語に比べてrustはまだまだ日本語の情報が限られているため誰かの役に立つかもしれない。
ただし以下は本記事のスコープ外としたい。経験年数わずか一ヶ月の人間が語るには説得力に欠けるように思う。
- gothamにおけるtokio 1.0対応のための変更
- tokio1.0が関連ライブラリに与える影響
本記事の想定読者は、
- 最近rustを使い始め」ており、
- 「rustでwebサーバーを作る」モチベーションがあって、
- さらに「gotham」の利用を検討している人
あたりになるだろうか。
ちなみにtokio1.0がリリースされたのは昨年12月で、gothamでもつい3週間前ほどにtokio1.0対応を完了している。 PRの内容を見ればすぐに分かるが、gothamではそれほど大きな変更は発生していないように伺える*1。
gothamを使う理由
じつのところ当初はgothamの利用は考えておらず、WebサーバーのHyperの上に最低限のスタックを自前実装するつもりでいた。
作成するrustサービスはリソースがごく限られている環境での動作を想定していたため、Ruby on Railsのようなフルスタックなフレームワークは避けたかったからだ。 また記事タイトルにも入れたtokioのrelated-projectsでもHyperが一番上に挙げられていたことも大きい。
Hyperは"Low-level"と自ら謳っているほど最低限の機能しか持たないwebフレームワークWebサーバーだ。
例えばurl(path)とリクエストハンドラを紐付ける機構すら存在せず、必要に応じでルーティング処理を自前実装するか、あるいはルーターライブラリを導入する必要がある。
しばらくはrustの練習も兼ねて自前実装を重ねていたが、ヤクの毛刈りあるいは車輪の再開発に没頭していることに途中で気がつき、結局はgothamの導入を決心した。
gothamはHyperの上で動くWebフレームワークだ。rustであれば当然期待する静的型付けはもちろん、tokioをベースとしたグリーンスレッドによる非同期処理を前提としている。
特筆すべきは、安定性をfeatureとして挙げていることかもしれない。 gothamはrustのbetaやnightlyバージョンでのテスト/ビルドもCIに取り入れており、日々活発な開発が進むrustに対して安定的に追従してくれるのはとてもありがたい。
Quick Tour
gothamのオフィシャルサイトにあるQuick Tourが良くできている。Hello WorldからSharing Stateまでタブを左から順にこなせば*2gothamがどのようなフレームワークなのか理解できる。
各セクションの概要に触れておくと、
- Hello world
- リクエストハンドラを1つの関数として実装する最もシンプルな内容
- Routing
- gothamが備えるrouter機構を利用するチュートリアル
- 各リクエストハンドラの実装はgithubリポジトリに存在する
- Extractors
- リクエストパラメータを使う方法の説明
- 各リクエストハンドラはstate呼ばれるオブジェクトしか受け取れない点がポイント
- Middleware
- リクエストハンドラの前後に処理を挟む方法を学ぶ
- 後続のSharingStateでもmiddlewareを用いており、じつはこの節がとても重要
- SharingState
- 共有メモリを使ってステートフルにリクエストを扱う方法を学ぶ
ご覧の通りQuick Tourではgothamの機能にざっくりと触れる程度の内容にとどまっている。
例えばQuick Tourでは共有メモリを用いたステートフル処理の実装に触れているが、実際のユースケースではむしろ外部のDBMSやKey-Valueデータストア等と連携させる場合が多い。
そこで以下のセクションでは、Quick Tourではカバーされていないが、しかしWebサービスとしては最低限必要となるであろう機能をどのように実現するかを説明する。
外部データの参照・変更
じつはgothamのexamplesディレクトリにはORMライブラリdieselの利用例が存在している。データベースと接続して何らかの処理を行いたい場合はこちらの例を参照すると便利だ。
dieselの例や他のexampleを見てみると分かるが、gothamではmiddlewareを通じて各リクエストハンドラに対して外部データへの参照を渡すのが一般的なようだ。例えばKey-Valuストアとの接続を渡す場合にもmiddlewareを使うことになるだろう。
以下ではdieselの例を使い、外部データ(以下の例でのRepo構造体)がリクエストハンドラまでどのようにして渡されるのかを確認していく。
まずはエントリポイントであるmain関数から見ていく。
gotham::start(addr, router(Repo::new(DATABASE_URL)));の行でrouter関数に対してRepo構造体を渡している。
/// Start a server and use a `Router` to dispatch requests fn main() { let addr = "127.0.0.1:7878"; println!("Listening for requests at http://{}", addr); gotham::start(addr, router(Repo::new(DATABASE_URL))); }
Repo構造体はgotham_middleware_diesel::Repo<SqliteConnection> のエイリアス(別名)になっていて、これ通してrepo.run(|conn| { do_something(); })のようにORMの機能を利用できる。
pub type Repo = gotham_middleware_diesel::Repo<SqliteConnection>;
router関数ではmiddlewareを挟み込んだり、それぞれのパスに対応するリクエストハンドラを紐付けている。
引数として受け取ったrepoが、各リクエストハンドラ get_products_handler create_product_handler ではなく、DieselMiddlewareに渡されている点に注意されたい。
fn router(repo: Repo) -> Router { // Add the diesel middleware to a new pipeline let (chain, pipeline) = single_pipeline(new_pipeline().add(DieselMiddleware::new(repo)).build()); // Build the router build_router(chain, pipeline, |route| { route.get("/").to(get_products_handler); route.post("/").to(create_product_handler); }) }
DieselMiddlewareはリクエストハンドラが引数として受け取るstateに対してrepoを埋め込むmiddlewareだ。 middlewareの仕組みを用いることで、リクエストハンドラは高階関数などのテクニックに頼らずともstate経由で簡単に外部データを参照・変更できる。
自分は長らくTypeScript, JavaScriptを書いていたこともあり、rustにおいても高階関数やクロージャに頼って書こうとする傾向があった。rustは厳密な型検証を行うためTS, JSと比べて関数渡しが難しいのだが、gothamを使い始めた当初は頭の切り替えができずに苦労していた。
さて、DieselMiddlewareの具体的な処理はMIddlewareトレイトで要求されるcallメソッドに書いてある。 とくに難しいことはしておらず、素直にrepoをstateに埋め込んでからリクエストハンドラへと渡している。
impl<T> Middleware for DieselMiddleware<T> where T: Connection + 'static, { fn call<Chain>(self, mut state: State, chain: Chain) -> Pin<Box<HandlerFuture>> where Chain: FnOnce(State) -> Pin<Box<HandlerFuture>> + 'static, Self: Sized, { trace!("[{}] pre chain", request_id(&state)); // repoをstateに埋め込む state.put(self.repo.clone()); // リクエストハンドラへと渡す let f = chain(state).and_then(move |(state, response)| { { trace!("[{}] post chain", request_id(&state)); } future::ok((state, response)) }); f.boxed() } }
最後にリクエストハンドラがstateからrepoを取り出している部分を見ておく。
fn get_products_handler(state: State) -> Pin<Box<HandlerFuture>> { use crate::schema::products::dsl::*; let repo = Repo::borrow_from(&state).clone(); // ここでrepoを取り出す async move { let result = repo.run(move |conn| products.load::<Product>(&conn)).await; match result { Ok(users) => { let body = serde_json::to_string(&users).expect("Failed to serialize users."); let res = create_response(&state, StatusCode::OK, mime::APPLICATION_JSON, body); Ok((state, res)) } Err(e) => Err((state, e.into())), } } .boxed() }
ここまでgothamにおいてリクエストハンドラに外部データを渡す方法をみてきた。
middlewareはリクエストハンドラの前後に処理を挟める汎用性の高い枠組みだ。 middlewareを活用すれば、外部データの注入以外にも、ビジネスロジックの外側にある関心事に対してうまく対処できる。
CORS
CORS(Cross-Origin Resource Sharing)はその名の通り、origin(取得するデータの配信元)をまたいだ処理を実現するための仕組みだ。 身近な例で言えば、SPAを開発する際にAPIサーバー側でCORSを有効化する必要があったりする。
CORSを有効化するためにはpreflightやリクエストヘッダ、レスポンスヘッダへの適切なフィールド設定が必要になる。 CORSそのものの詳細な説明は参照記事に委ねたい。
さて、RubyならRails、NodeJSであればExpressといったようなメジャーなWebフレームワークではCORSが簡単に実現できる。 多くの場合はミドルウェアとしてCORS有効化の機構が提供されている。
- express: https://expressjs.com/en/resources/middleware/cors.html
- rails: https://github.com/cyu/rack-cors
当然、rust/gothamでも同様のミドルウェアの存在を期待するのだが意外に適当なものが見つからなかった。 正確に言えばひとつだけgotham-cors-middlewareなる存在を確認できたのだが、残念ながらgotham 0.2で開発が止まっていた。
前述の通りSPAの開発時などはとくにCORSが有効になっていないと不便に感じる。 例に漏れず自分の場合もCORSが必要になったため、gotham-cors-middlewareをforkしてgotham0.5に対応させた*3。gothamでサクッとCORS対応させたい方は是非使っていただきたい。
じつは本プラグインもmiddlewareとして実装されている。受信したリクエストのヘッダから特定の情報を抜き出し、適当に整形したあとでレスポンスのヘッダに埋め込んでいる。
おわり
rustを使い始めてまだわずかしか経っていないが、早くもrustの可能性に驚いている。
c/c++で行っていたようなメモリ管理等の低次のレイヤから、rubyやjsのような高度に抽象化されたレイヤにおける処理まで、一気通貫で書き記せるためとても気持ちがいい。 「それ、goでもできるよ」と一蹴されてしまいそうだが、ガベージコレクションやゼロコスト抽象の有無によってrustではgo以上の高速化が望める点も大きな強みに思う。 関数型のパラダイムを積極的に取り入れているのもgoとの差異だろう。
逆にrustを書いていて不満に感じるのはなんと言ってもコンパイルの遅さだ*4。 rustでは書く→試すのイテレーションを(時間的にも・心理的にも)細かく回すことができないため、軽量プログラミング言語に慣れている人間には相当なストレスになりそうだ。
k3sでGitHub Container Registryにおいたプライベートなコンテナイメージをつかう
内容を整理していて気づいたが、本記事には
- (A) k3sでprivateなコンテナレジストリを使う
- (B) Github Package Registry (GPR)からGithub Container Registry (GHCR *1 )へ移行する
という2つのトピックが混ざっていることに気が付いた。備忘録も兼ねて先にアウトラインを示しておく。
(A) k3sでprivateなコンテナレジストリを使う
- k3sとは一言で表せばシングルバイナリの軽量Kubernetes
- エッジ環境やCIなどリソースが限られた状況を想定して作られている
- Rancher(kubernetesのめんどくさい設定をまるっと良しなにやってくれる君)を開発しているRancher社がk3sも開発している
- 本記事執筆中に公式ドキュメントの日本語訳をみつけた
- k3sは標準のコンテナランタイムとしてcontainerdを採用している
- ちなみにdockershim経由でdockerを使うことも可能
- k3sでprivateなコンテナレジストリを利用するにはk8sのそれとは異なる方法を取る必要がある
- じつはしばらくの間、containerdではGPRからdockerイメージをpullできない問題があった
- そのためk3sでprivteコンテナレジストリの設定を行ってもGPRからdockerイメージをpullできなかった
- 問題の原因はGithub側にあったのだが、2020年にGPRのdockerイメージレジストリがGHCRへと切り出された際に解決した
- ref. containerd can't pull image from Github Docker Package Registry · Issue #3291 · containerd/containerd · GitHub
(B) Github Package Registry (GPR)からGithub Container Registry (GHCR)へ移行する
- Github Package RegistryとはGithub社で提供しているパッケージレジストリ
- Github Actionsと組み合わることでコードベース管理からレジストリ登録までgithubで完結できる
- Github Container Registryとは同じくGithub社が提供するコンテナレジストリ
- オフィシャルアナウンス曰く、
GitHub Container Registry improves how we handle containers within GitHub Packages. With the new capabilities introduced today, you can better enforce access policies, encourage usage of a standard base image, and promote innersourcing through easier sharing across the organization.
- とのことだが、後述するとおり基本的にはGPRでDocker imageをホスティングするのと使い方は大きく変わらない。DockerHubやAmazon Elastic Container Registryなどと同じ位置づけ
- まだpublic beta段階なので利用するには機能の有効化が必要
- publicなコンテナイメージに対しては無料利用でき、public bataのフェーズの間はprivateなものも無料で利用できる。generally availableになったあともGPRと同じ課金モデルで提供予定とのこと
- オフィシャルアナウンス曰く、
- Github Actionをつかってdockerイメージをビルド、およびGHCRへイメージをpushするならdocker/build-push-actionを使うのが簡単
- github.com
- GHCRにpushするにはコンテナイメージのtagは
ghcr.io/接頭辞としてもつ必要がある
ここで今一度、takeawayを要約すると
- Github Container Registry (GHCR)に置いたprivateコンテナイメージならk3sから利用できる
- docker/build-push-action@v2を使ってGHCRにコンテナイメージをpushするには、(1)事前に機能の有効化を行い、(2)tagには
ghcr.io/接頭辞としてつける
ということになる。
それでは次から具体的な方法を示していく。
ちなみにk3sはARMでも動くと謳っているが、本記事ではx86系のプロセッサで動く環境を前提とする*2。 本記事で利用したコードをこちらのリポジトリにまとめた。
1. Github Actionを用いたGHCRへのコンテナイメージ登録
流れとしては以下の4ステップ。
- 1-a. 適当なプログラムとDockerイメージを生成するDockerfileの用意
- 1-b. GHCRの有効化
- 1-c. GHCRの認証用にPAT(Private Access Token)の発行
- 1-d. GithubActionでdocker/build-push-action@v2を使うための設定
基本的にはリファレンスを張りつつ注意書き程度の補足を記すが、サンプルコードと合わせて確認してもらいたい。
1-a. 適当なプログラムとDockerイメージを生成するDockerfileの用意
Hello!の文字列と現在時刻を4秒ごとに履き続けるjsスクリプトをDockerイメージとして用意する。 長々と述べるよりもcommitログを見るほうがわかりやすいように思う。
1-b. GHCRの有効化
オフィシャルドキュメントにて画像添付で解説されているので参考にされたい。PersonalとOrganizationとで有効化ボタンが2箇所あるので注意。
なお、これを忘れると後述するGHCRへのコンテナイメージpushが失敗する。
1-c. GHCRの認証用にPAT(Private Access Token)の発行
オフィシャルでGITHUB_TOKENではなくPATを利用するように書かれている。
If you want to authenticate to GitHub Container Registry in a GitHub Actions workflow, then you must use a personal access token (PAT).
PATの作成方法はこちらから。
作成したPATをセキュアにGithub Actionに渡すには secrets という仕組みを利用する。
PATとは異なり、secretsはリポジトリごとあるいはOrganizationごとに登録する。登録した値をGithub Actionから${{ secrets.SuperSecret }} のようにして参照する。
1-d. GithubActionでdocker/build-push-action@v2を使うための設定
v1 から v2 へとアップデートした際に大きな仕様変更があり、v2では レジストリログイン と ビルド環境セットアップが別actionに切り出された。
とはいえ設定項目が難しくなった訳でもないので素直にREADME.mdに従ってworkflowを書けば良い。
なお、v1にあった便利な tag_with_ref が使えなくなってしまった。そのためコンテナイメージへのタグ付けは他のアクションで賄う必要がある*3。
name: deploy
on:
push:
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Login to GitHub Container Registry
uses: docker/login-action@v1
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GHCR_PAT }} # secret経由でPATを渡す
- name: Get smart tag # このstepはオプショナル。v1の`tag_with_ref`と同等の機能
id: prepare
uses: Surgo/docker-smart-tag-action@v1
with:
docker_image: ghcr.io/${{ github.repository }}/test # `ghcr.io`を接頭辞にすること
- name: Build and push
uses: docker/build-push-action@v2
with:
push: true
context: .
tags: ${{ steps.prepare.outputs.tag }} # 前ステップ(prepare)で用意したタグ名を使う
build-args: NODEJS_VERSION=14.10.0-slim
cache-from: type=registry,ref=ghcr.io/${{ github.repository }}/test:develop
cache-to: type=inline
2. Privateレジストリの設定とk3sのインストール
k3sでプライベートレジストリを利用するには、事前に所定のパスに設定ファイルを配備する*4。具体的には /etc/rancher/k3s/registries.yaml に以下の内容でファイルを置く。
$ cat /etc/rancher/k3s/registries.yaml
mirrors:
ghcr:
endpoint:
- "https://ghcr.io"
configs:
"ghcr.io":
auth:
username: sat0yu
password: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
username にはGithubアカウント、passwordにはPATを指定する。ここで使うPATは read:packages 権限があれば十分で、GHCRにコンテナイメージをPushするときのものと異なっていても良い(むしろ別にしたほうが安全。)
オフィシャルドキュメントを見るとhttpsならTLSに関する設定が必須のように誤解しそうだが、上記のようにTLSフィールドを省略しても正常にイメージをpullできた。
registries.yaml が用意できたらk3sのインストールを行う。k3sのインストールはワンライナーで済む。
$ curl -sfL https://get.k3s.io | sh - [INFO] Finding release for channel stable [INFO] Using v1.20.0+k3s2 as release [INFO] Downloading hash https://github.com/rancher/k3s/releases/download/v1.20.0+k3s2/sha256sum-amd64.txt [INFO] Downloading binary https://github.com/rancher/k3s/releases/download/v1.20.0+k3s2/k3s [INFO] Verifying binary download [INFO] Installing k3s to /usr/local/bin/k3s [INFO] Creating /usr/local/bin/kubectl symlink to k3s [INFO] Creating /usr/local/bin/crictl symlink to k3s [INFO] Skipping /usr/local/bin/ctr symlink to k3s, command exists in PATH at /usr/bin/ctr [INFO] Creating killall script /usr/local/bin/k3s-killall.sh [INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh [INFO] env: Creating environment file /etc/systemd/system/k3s.service.env [INFO] systemd: Creating service file /etc/systemd/system/k3s.service [INFO] systemd: Enabling k3s unit Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service. [INFO] systemd: Starting k3s
k3sはkubectlが同梱していて、正常にインストール完了するとkubectlコマンドにsymlinkがはられる。
kubectl get nodeで動作を確認しておく。
$ ls -al /usr/local/bin/kubectl lrwxrwxrwx 1 root root 3 Jan 18 14:06 /usr/local/bin/kubectl -> k3s $ sudo kubectl get node NAME STATUS ROLES AGE VERSION xxxx Ready control-plane,master 32s v1.20.0+k3s2
3. k3sクラスタへのpodデプロイ
全ステップまでですでにk3sクラスタ*5を立ち上げた状態になっている。
マニフェストファイルに特別な記述は必要なく、適切なimageを指定すれば良い。
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
replicas: 1
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: test
image: ghcr.io/sat0yu/k3s-with-private-container-images-in-gcr/test:master
imagePullPolicy: Always
command: ["yarn", "start"]
あとはマニフェストファイルをapplyしてk8sがコンテナイメージをpullしてデプロイが完了させる。
$ sudo kubectl apply -f deployment.yaml deployment.apps/test configured
最後に期待通りコンテナが動いているか確認する
$ sudo kubectl get po NAME READY STATUS RESTARTS AGE test-85b8b88944-grmsk 1/1 Running 0 2m22s $ sudo kubectl logs -f -l app=test hello! Mon Jan 18 2021 23:44:58 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:02 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:06 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:10 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:14 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:18 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:22 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:26 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:30 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:34 GMT+0000 (Coordinated Universal Time) hello! Mon Jan 18 2021 23:45:38 GMT+0000 (Coordinated Universal Time)
*1:GCRだとContainer Registry | Google Cloudと紛らわしい
*2:確認していないがDockerfileにあるnodeのベースイメージを適切なものに変更すればARMでも動くと思う
*3:サンプルコードではSurgo/docker-smart-tag-actionを利用した
*4:マニュアルによればk3s起動時に--private-registryオプションでパスを指定することも可能らしい
*5:k3sで立ち上げるk8sクラスタ?
Minikube 1.16.0 (Kubernetes 1.20.0) にアップグレードしたらReadinessProbeがfailした
背景と問題
- Minikube 1.12.3をデフォルト設定 (Kubernetes v1.18.3)で利用していた
- Readiness Probeとしてexecフィールドに内製スクリプトを指定していた(スクリプトの実行にかかる時間は約2秒)
- 先日、Minikube 1.16.0にアップグレードした途端にReadiness Probeが失敗しだした
原因
- Minikube 1.16.0はデフォルトでKubernetes v1.20.0を利用する
- Kubernetes v1.20.0で
timeoutSecondsのデフォルト値として1 secondが指定される
学び
(dockershimのとき) timeoutSeconds フィールドが無視されていた
https://github.com/kubernetes/kubernetes/pull/94115
このPRによって timeoutSeconds が有効化されたのだけど、それと同時にexec型のreadiness/liveness probeにデフォルトで1秒タイムアウトが生まれた
readiness probe および liveness probeのログは journalctl -u kubelet 経由でアクセス可能
readiness/liveness probeのログは kubectl describe pod {YOUR_POD} の最下部にeventとして入ってくるが、情報量が少なくエラー追跡しづらい。せいぜいprobeの成功・失敗程度の情報しか得られず調査が進められなかった。
途中でprobeがkubeletによって実行される(ヘルスチェック対象のpodが実行する訳ではない)ことを思い出し、journalctlで見てみたところ DeadlineExceeded の文字列を発見。その後、https://kubernetes.io/blog/2020/12/08/kubernetes-1-20-release-announcement/#exec-probe-timeout-handling に行き当たり解決することができた。
xxx@xxxxx:~$ sudo journalctl -u kubelet -f -- Logs begin at Thu 2020-11-05 03:45:00 UTC. -- Jan 12 06:11:47 rams kubelet[2763501]: E0112 06:11:47.967431 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:12:02 rams kubelet[2763501]: E0112 06:12:02.972673 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:12:17 rams kubelet[2763501]: E0112 06:12:17.967784 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:12:32 rams kubelet[2763501]: E0112 06:12:32.966427 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:12:47 rams kubelet[2763501]: E0112 06:12:47.966576 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:13:02 rams kubelet[2763501]: E0112 06:13:02.968304 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:13:17 rams kubelet[2763501]: E0112 06:13:17.965255 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:13:32 rams kubelet[2763501]: E0112 06:13:32.967139 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:13:47 rams kubelet[2763501]: E0112 06:13:47.964895 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jan 12 06:14:02 rams kubelet[2763501]: E0112 06:14:02.969880 2763501 remote_runtime.go:392] ExecSync bc2ef37c1e3bcea3afe12a27c9b52340bb427e111b2e7d6245b12b0b22bb17a5 'yarn mqtt-healthchecker' from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
具体的には以下のいずれかで解決可能
timeoutSecondsに適切な値を設定- 今回はこちらの方法を選択して事なきを得た
ExecProbeTimeoutを無効化
蛇足
readiness probeのexecコマンドで使っていたのは拙作npmモジュール www.npmjs.com
システムの目的を忘れないこと
これは30日チャレンジの17日目(2019/09/25)に書かれた文章です
あらゆるシステムにおいて、ユーザが入力可能な値が増えるほどシステムの複雑性が高まる。 こうして見るとあえて文字に起こすほどのことでもないが、新規のシステムや機能を検討している段階において本主張はしばし見過ごされることがある。 あるいは「そもそもこの値はユーザから入力してもらう必要があるのか」という問いを立て、What‐何を創るかを洗練させることができるエンジニアは少ないのではなかろうか。
筆者はいま、来春リリースを見据えた新たなアプリケーションの開発に携わっており、本日もチームメンバーと機能の検討を行った。 議論の中で、ある機能をスコープから外すと一気に設計がシンプルになるモデルが発見された。
一言で説明すれば、それは時間割を表現するモデルで、機能としてはユーザごとに自らが作成した時間割にもとづく進捗管理を行う。 では一体どうして、時間割モデルをスコープから外すと大きく設計が簡潔になるのだろうか。
続きを読むリファクタリングをしたいエンジニア
これは30日チャレンジの16日目(2019/09/24)に書かれた文章です
新規事業においては、プロダクトの方向性が変わったり、当初は想定していなかった機能が増えたり、What―何を創るのかという点の不確実性が大きい。 結果として、コンポーネントの責務範囲が曖昧になることでコード全体の品質が低下する。 類似のコードがそこかしこに偏在に、保守性が低く、バグの温床になりやすい。
経験や知識に裏打ちされた洞察でWhatの部分想像したり、適切なデザインパターンを採用することで、不確実性に起因するコード品質の低下を防ぐ努力はできる。 しかしながら、どれほど優れたエンジニアであってに、本質的に新規事業の未来を予見することは不可能だ。 むしろ刻々と変化するビジネスに追従・先回りできるだけの柔軟性と機敏性を保つことに心血を注ぐべきだろう。
一方で、「防げる」種類の問題も存在する。それはかの有名な名言「早すぎる最適化」である。 これはHow―どうやって創るのかに関する不確実性と関係している。 Howは定義からしてWhatに準じる概念であり、Whatが定まらない限りはHowの不確実性も収束しない。 しかし残念ながら、我々エンジニアという生き物はHowの不確実性を正しく認識できないらしい。
さまざまな理由が考えられるだろう。新しいデザインパターンを試してみたい、慣習に従うと数値型よりも文字列型のほうが便利だ、現状のままでも問題はないが煩雑としたコードベースを許せないなど、可能性はいくらでもある。 筆者が一番気に入っている比喩は手術好きの医者の例である。じつは一部の医者は「手術をしたい」と考えているのだそうだ。 自分が患者の身になったところを想像すれば、なんて恐ろしいことかと思うだろう。 しかし「手術が好き」で医者になった人間からすれば、当然手術をしたいと考えるし、そのような診断を下したとしても違和感のない話である。 同様にして、技術が好きでエンジニアになった人間が手術=リファクタリングをしたいと考えるのはごく自然なことだろう。 これが認知バイアスとなって働き、Howの不確実性を正しく認識することを妨げている可能性は否定できまい。
筆者が今、エンジニアとして新規事業の開発に携わっているという話はこれまでも何度か述べた。 じつは数週間前から細々と取り組んでいたリファクタリングがあったのだが、本日リファクタリングを元に戻すことが決定した。
主な理由は2つあった。
- (1)リファクタリング過程において複数の機能実装間でコードの一貫性が欠ける
- (2)不確実性の収束が期待できず後ほどまた別の変更が必要になる可能性が高い
(1)に関しては、近々多数のエンジニアがチームにジョインすることが決まっているため、コードベースの理解を妨げる要因を避けたいという外部状況も関係している。 そして注目すべきは(2)の理由で、まさに上で述べた議論に一致している。
今回、筆者が犯してしまった失敗は、WhatとHowの両方で不確実性が高い状態のままリファクタリングを進めてしまったことである。 「リファクタリングは(少なくともコードに改善する限りにおいて)良い習慣だ」という認識をもっており、不確実性の観点を十分に考慮に入れることができていなかった。 本経験をとおして、プロダクト開発における不確実性の考え方を一層深めることができた。